我原本以为我这样的菜鸟,如果想爬的话应该只能用xpath来爬取斗鱼图片,可是当我在爬取途中想获取地址,发现了很奇怪的现象 之后我去百度了,看到他们说斗鱼是哪js写的所以我xpath找不到… 所以我就去看了一下...
”python 爬虫 爬取斗鱼 python大作业“ 的搜索结果
所学Python技术设计并实现一个功能完整的系统,并撰写总结报告。 要求: (1)实现时需要至少使用图形界面、多线程、文件操作、数据库编程、网页爬虫、统计 分析并绘图(或数据挖掘)六项技术,缺一不可。少一项则...
我们通过抓包,分析那一大坨数据包,可以确定以下通过以下的流程便可以获取弹幕消息。(分析过程比较繁琐)首先建立两个Socket。一个用于认证(@danmu_auth_socket),另一个用户获取弹幕(@danmu_client)。步骤1: @...
Python崛起并且风靡,因为优点多、应用领域广、被大牛们认可。学习 Python 门槛很低,但它的晋级路线很多,通过它你能进入机器学习、数据挖掘、大数据,CS等更加高级的领域。Python可以做网络应用,可以做科学计算,...
斗鱼一:前言这些天一直想做一个斗鱼爬取弹幕,但是一直考试时间...代码地址:这次爬取的房间是斗鱼直播的芜湖大司马,因为他人气比较多,方便分析。主播也是我老乡,嘿嘿。然后把弹幕的信息的uid,昵称,等级,弹...
首先我准备利用mysql来存储我爬取的信息,建一个host表如下:然后下载pymysql ,利用它与数据库链接,因为在这里我只涉及到写入的操作:Unit_Mtsql然后就是使用Beautifulsoup框架对斗鱼的链接进行解析,为了使用的...
能够完成上述功能的都可以称为爬虫,目前主流的Python爬虫框架主要分为调度器、URL管理器、网页下载器、网页解析器、应用程序(爬取的有价值数据)。调度器主要来调度管理器、下载器和解析器;URL管理器主要用来管理...
分析斗鱼的翻页,有一个下一页按钮,是个li,class=dy-Pagination-item-custom ,但是当烦到最后一页的时候,class=dy-Pagination-disabled dy-Pagination-next,所以我们要想利用selenium模拟点击这个按钮,我们...
爬取豆瓣影评保存到Excel文件中
首先我准备利用mysql来存储我爬取的信息,建一个host表如下: 然后下载pymysql ,利用它与数据库链接,因为在这里我只涉及到写入的操作...获取斗鱼的几大模块,斗鱼一共有7个模块:网游晋级,单机热,手游休闲等...
from time import sleep import requests ...# 爬取分类页面数据 #获取斗鱼分类页面数据 def get_directory(): #获取网页 url = 'https://www.douyu.com/directory' html = requests.get(ur...
爬取斗鱼直播照片保存到本地目录【附源码】
Python爬虫源码大放送:抓取数据,轻松搞定! 想轻松抓取网站数据,却苦于技术门槛太高?别担心,这些源码将助你轻松搞定数据抓取,让你成为网络世界的“数据侠盗”。 它们还具有超强的实用价值。无论你是想要分析...
在网上找到了一份斗鱼弹幕服务器第三方接入协议v1.6.2,有了第三方接口,做起来就容易多了。一、协议分析斗鱼后台协议头设计如下:这里的消息长度是我们发送的数据部分的长度和头部的长度之和,两个消息长度是一样。...
大数据之如何利用爬虫爬取数据做分析
爬取知乎热榜Top50保存到Excel文件中
还是分析一下大体的流程:首先还是Chrome浏览器抓包分析元素,这是网址:...然后在对每个element逐一操作分析斗鱼的翻页,有一个下一页按钮,是个li,class="dy-Pagination-item-custom",...
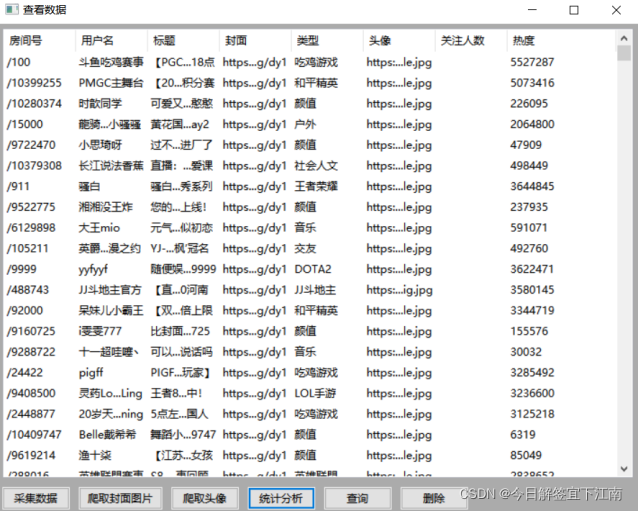
爬取斗鱼直播网站信息,如直播名字、主播名字、热度、图片和房间网址,将这些数据保存到csv文件中,并单独创建文件夹保存图片。 斗鱼直播网址:https://www.douyu.com/g_LOL 二、分析url 先单击【直播】,然后...
爬虫案例、爬取酷狗音乐排行榜、爬虫top500
python爬虫爬取斗鱼网站信息 # _*_ coding:utf-8 _*_ #模拟js翻页爬取斗鱼直播页面 #导入测试模块 import unittest #导入webdriver from selenium import webdriver #导入键盘操作keys包 from selenium....
最近看到斗鱼里的照片都不错,决定用最新学习的python技术进行爬取,下面将实现的过程分享出来供大家参考,下面话不多说了,来一起看看详细的介绍吧。方法如下:首先下载一个斗鱼(不下载也可以,url都在这了对吧)...


0.前言前几天(寒假前咯)闲着无聊,看到舍友们都在看斗鱼TV,虽然我对那些网络游戏都不是非常感兴趣,但是我突然间想到,如果我可以获取上面的弹幕内容,不就有点意思了么?1.分析阶段如果我想要抓取网页上面的东西,...
import jsonimport jsonpathimport requestsimport time,rebese_url = "https://www.douyu.com/gapi/rkc/directory/0_0/{}"head = {"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML,...
原标题:Python爬虫:利用API实时爬取斗鱼弹幕这些天一直想做一个斗鱼爬取弹幕,但是一直考试时间不够,而且这个斗鱼的api接口虽然开放了但是我在github上没有找到可以完美实现连接。我看了好多文章,学了写然后总结...
import json import jsonpath import requests import time,re bese_url = "... head = { "user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (...
原标题:[Python爬虫]使用Python爬取静态网页-斗鱼直播好久没更新Python相关的内容了,这个专题主要说的是Python在爬虫方面的应用,包括爬取和处理部分第一节我们介绍如何爬取静态网页[Python爬虫]使用Python爬取...
function:斗鱼网站的爬取 “”" import time from selenium import webdriver class DouYu(object): def __init__(self): self.url = "https://www.douyu.com/directory/all" options = webdriver.ChromeOptions()...
推荐文章
- Android RIL框架分析-程序员宅基地
- Python编程基础:第六节 math包的基础使用Math Functions_ps math function-程序员宅基地
- canal异常 Could not find first log file name in binary log index file_canal could not find first log file name in binary-程序员宅基地
- 【练习】生成10个1到20之间的不重复的随机数并降序输出-程序员宅基地
- linux系统扩展名大全,Linux系统文件扩展名学习-程序员宅基地
- WPF TabControl 滚动选项卡_wpf 使用tabcontrol如何给切换的页面增加滚动条-程序员宅基地
- Apache Jmeter常用插件下载及安装及软硬件性能指标_jmeter插件下载-程序员宅基地
- SpringBoot 2.X整合Mybatis_springboot2.1.5整合mybatis不需要配置mapper-locations-程序员宅基地
- ios刷android8.0,颤抖吧 iOS, Android 8.0正式发布!-程序员宅基地
- 【halcon】C# halcon 内存暴增_halcon 读二维码占内存-程序员宅基地